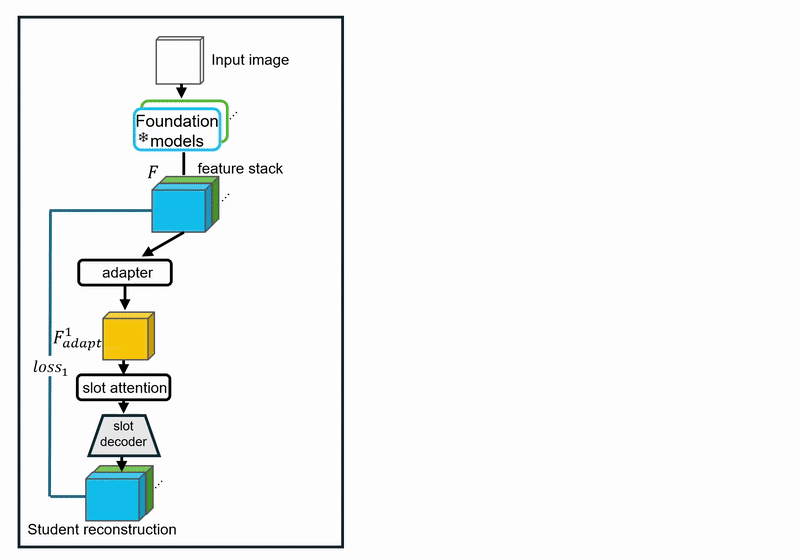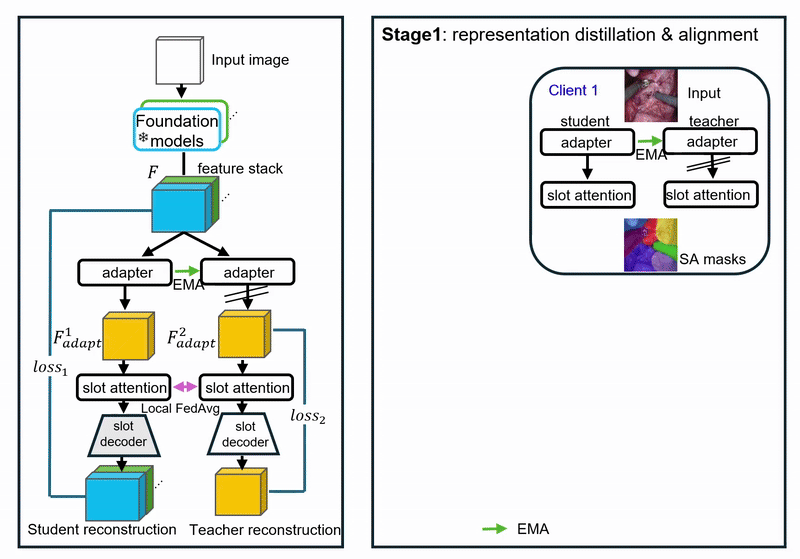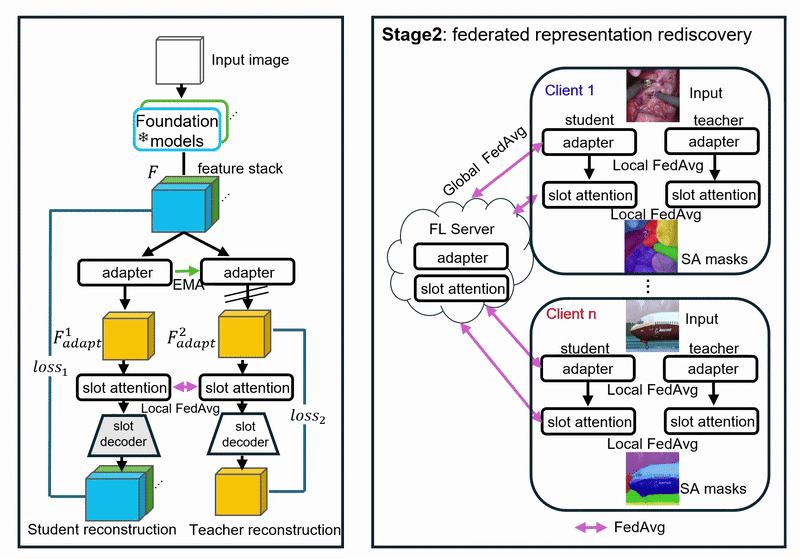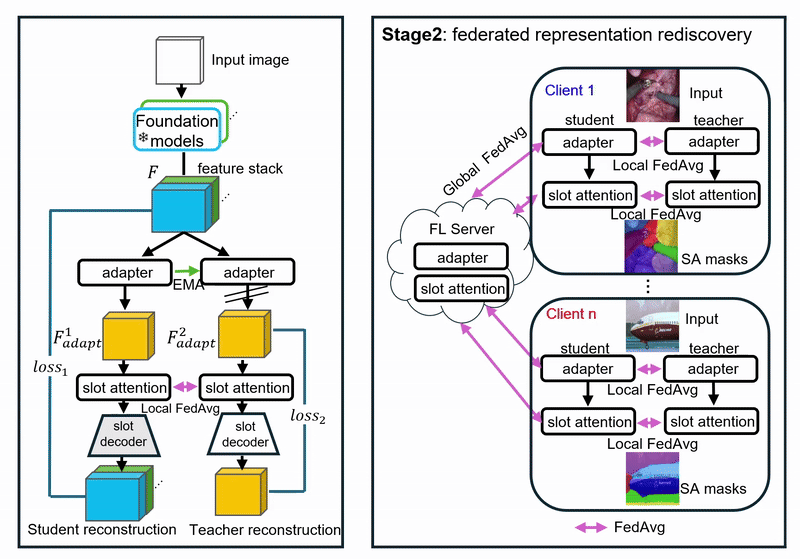
Challenges
(1) Learn features jointly informative across clients with no labels.
(2) Disentangle client-specific factors while preserving shared object structure.

| Input | SAM (SA adapted) | DINO (SA adapted) | FORLA |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |


@article{liao2025forla,
title = {FORLA: Federated Object-Centric Representation Learning with Slot Attention},
author = {Liao, Guiqiu and Jogan, Matjaž and Eaton, Eric and Hashimoto, Daniel A.},
journal = {NeurIPS},
year = {2025}
}